文章摘要:随着大数据与人工智能技术在体育领域的深度融合,基于多维度体育比赛数据统计的分析与应用研究逐渐成为推动体育科学发展和竞技水平提升的重要手段。本文围绕“基于多维度体育比赛数据统计的分析与应用研究模型构建与趋势预测探讨”这一核心主题,从数据基础、模型构建、应用实践以及未来趋势四个层面展开系统论述。文章首先阐明多维度体育比赛数据的内涵与特征,强调数据采集、整合与质量控制在分析中的基础性作用;随后深入探讨统计分析方法与智能模型构建思路,剖析传统统计与现代算法的融合路径;在此基础上,结合实际应用场景,论证数据分析模型在竞技决策、训练优化与赛事管理中的现实价值;最后对体育数据分析模型的发展趋势进行前瞻性展望。通过系统梳理与综合分析,本文力求为体育比赛数据统计分析的理论研究与实践应用提供具有参考价值的框架与思路。
一、多维数据基础认知
多维度体育比赛数据是指在比赛与训练过程中,从时间、空间、技术、战术、生理和心理等多个维度采集并形成的数据集合。这类数据突破了传统单一统计指标的局限,使研究者能够从更立体的视角理解运动表现与比赛结果之间的关系。
在实际应用中,多维数据的来源十分广泛,包括比赛技术统计、运动员生理监测数据、视频与轨迹数据以及环境因素数据等。不同数据类型在结构、精度和时效性方面存在显著差异,这对后续分析提出了更高要求。
因此,在开展分析研究之前,必须对数据进行系统梳理和标准化处理。通过建立统一的数据描述体系和指标框架,才能确保多维数据在同一分析模型中具有可比性和可解释性。
此外,多维数据的价值不仅体现在数量和维度的扩展上,更体现在其关联性与交互性。只有充分挖掘不同维度数据之间的内在联系,才能为模型构建和趋势预测提供坚实基础。
二、统计模型构建思路
基于多维度体育比赛数据的统计分析模型构建,是将复杂数据转化为可理解、可预测信息的关键环节。模型构建首先需要明确研究目标,例如胜负预测、表现评估或风险预警,从而选择合适的分析路径。
传统统计方法在体育数据分析中仍具有重要价值,如回归分析、方差分析和相关分析等。这些方法在解释变量关系和验证假设方面具有清晰逻辑,为模型的可解释性提供了保障。
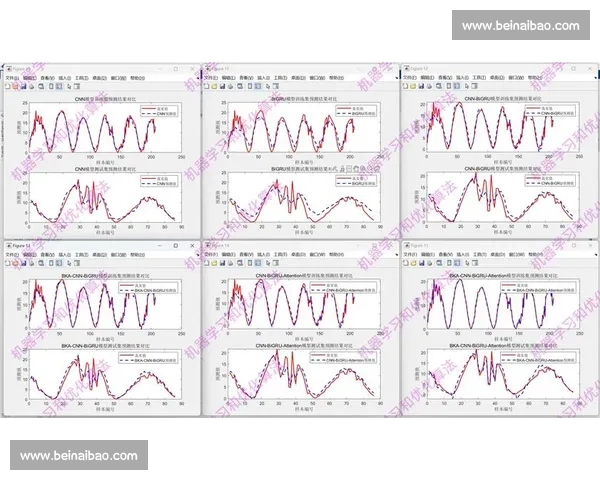
随着数据规模和复杂度的提升,机器学习与智能算法逐渐被引入模型构建过程。通过分类、聚类和预测算法,可以更有效地处理高维、非线性数据特征,提升模型的预测精度。
在实践中,往往需要将传统统计方法与智能算法进行融合。一方面保证模型结果具有统计学意义,另一方面增强模型对复杂比赛情境的适应能力,从而构建更加稳健的分析框架。
三、分析模型应用场景
多维度体育比赛数据分析模型在竞技体育中的应用,首先体现在比赛决策支持方面。通过对历史比赛数据的系统分析,教练团队可以更科学地制定战术方案和人员配置策略。
在运动训练领域,数据分析模型能够帮助精准评估运动员的技术特点和体能状态。基于多维数据的反馈机制,有助于实现个性化训练方案的设计,提高训练效率并降低伤病风险。
赛事管理与运营同样受益于数据分析模型的应用。通过对观赛行为、比赛节奏和市场反应等数据的分析,赛事组织者可以优化赛程安排和商业策略,提升赛事整体价值。
值得注意的是,模型应用的有效性高度依赖于结果解释与实践结合。只有将分析结论转化为可操作的决策建议,数据分析模型才能真正发挥其现实意义。
四、发展趋势与挑战
从发展趋势来看,体育比赛数据分析正朝着实时化、智能化和精细化方向演进。随着传感器和计算能力的提升,实时数据分析将成为比赛现场决策的重要支撑。
同时,模型构建将更加注重跨学科融合。体育科学、数据科学和行为科学的交叉,将为趋势预测提供更全面的理论支持,推动分析结果从“描述性”向“预测性”和“决策性”转变。

然而,多维度数据分析也面临诸多挑战。数据隐私与伦理问题、模型过拟合风险以及结果解释难度,都是制约其进一步发展的关键因素。
PA视讯平台下载,pa视讯集团官网首页,PA视讯集团网站,pa视讯平台,PA视讯官方集团因此,在追求技术进步的同时,必须建立完善的数据治理和模型评估机制,确保分析结果的科学性、公正性与可持续性。
总结:
综上所述,基于多维度体育比赛数据统计的分析与应用研究模型构建,是现代体育科学发展的重要方向。通过系统整合多源数据、构建科学合理的统计与智能模型,可以显著提升对比赛规律和运动表现的认知水平。
面向未来,随着技术条件的不断成熟,多维度数据分析模型将在竞技体育、群众体育和体育产业中发挥更加深远的影响。只有在理论研究与实践应用的良性互动中,才能不断完善模型体系,实现体育数据价值的最大化。